|
I am a third-year Ph.D. student in the Multi-Media Lab at The Chinese University of Hong Kong, supervised by Prof. Dahua Lin. My current research interest spans the vision-language model and object-centric video understanding. I obtained my Master's degree in Electrical Engineering from Shanghai Jiao Tong University in 2023, where I was advised by Prof. Hongkai Xiong. Prior to that, I earned a Bachelor's degree in Computer Science from the University of Michigan, along with a dual degree in Electrical and Computer Engineering from Shanghai Jiao Tong University in 2021. I was a Research Scientist Intern at Meta Superintelligence Labs (Segment Anything Team) under the mentorship of Nicolas Carion. I expect to graduate in Summer 2027. I am actively seeking internship and full-time Research Scientist opportunities and would love to connect regarding potential openings. Email / CV / Google Scholar / Github / Linkedin |

|
|
[Jan. 2026] Three papers have been accepted at ICLR 2026. [Nov. 2025] We released SAM 3, a unified model for detection, segmentation, and tracking of objects in images and video using text, exemplar, and visual prompts. [Aug. 2025] Invited talk at LSVOS workshop at ICCV 2025. [Jun. 2025] SAM2Long is accpeted at ICCV 2025. [May. 2025] SongComposer is accpeted at ACL 2025 main conference finally and SongGen is accepted at ICML 2025. [Mar. 2025] Three paper have been accepted at CVPR 2025. |
|
|
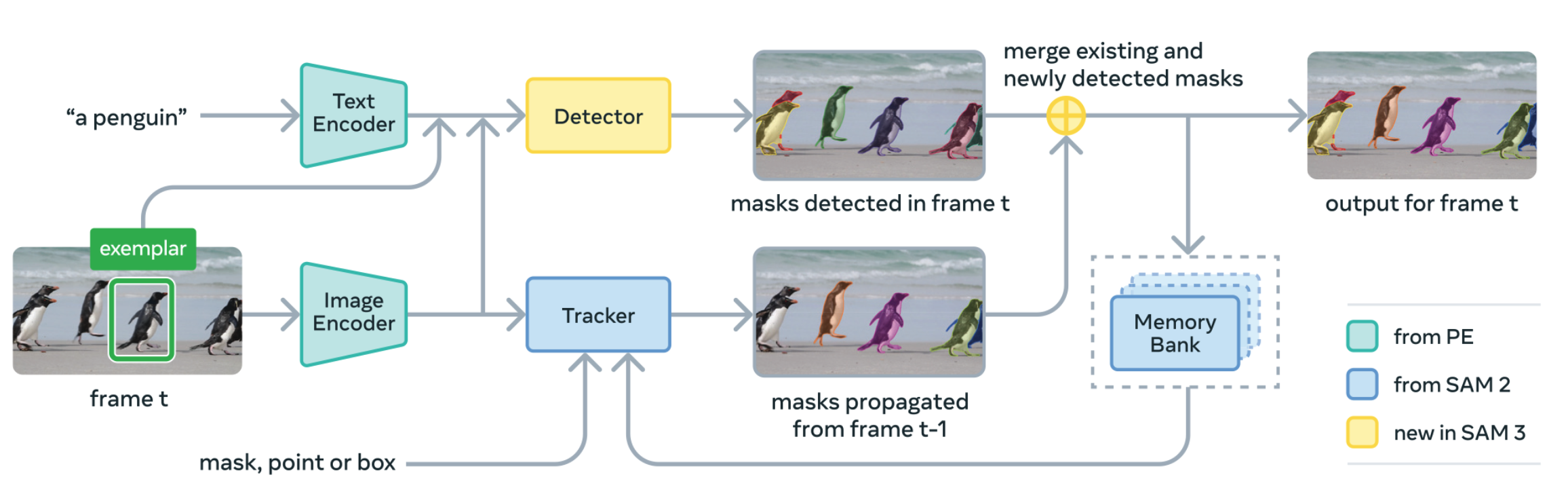
|
Nicolas Carion*, Laura Gustafson*, Yuan-Ting Hu*, Shoubhik Debnath*, Ronghang Hu*, Didac Suris*, Chaitanya Ryali*, Kalyan Vasudev Alwala*, Haitham Khedr*, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu°, Tsung-Han Wu°, Yu Zhou°, Liliane Momeni°, Rishi Hazra°, Shuangrui Ding°, Sagar Vaze°, Francois Porcher°, Feng Li°, Siyuan Li°, Aishwarya Kamath°, Ho Kei Cheng°, Piotr Dollar†, Nikhila Ravi†, Kate Saenko†, Pengchuan Zhang†, Christoph Feichtenhofer† ICLR, 2026 Project Page / paper / blog / demo / code / HF🤗 Unify detection, segmentation, and tracking of any concept in images and video using text and exemplar prompts. |

|
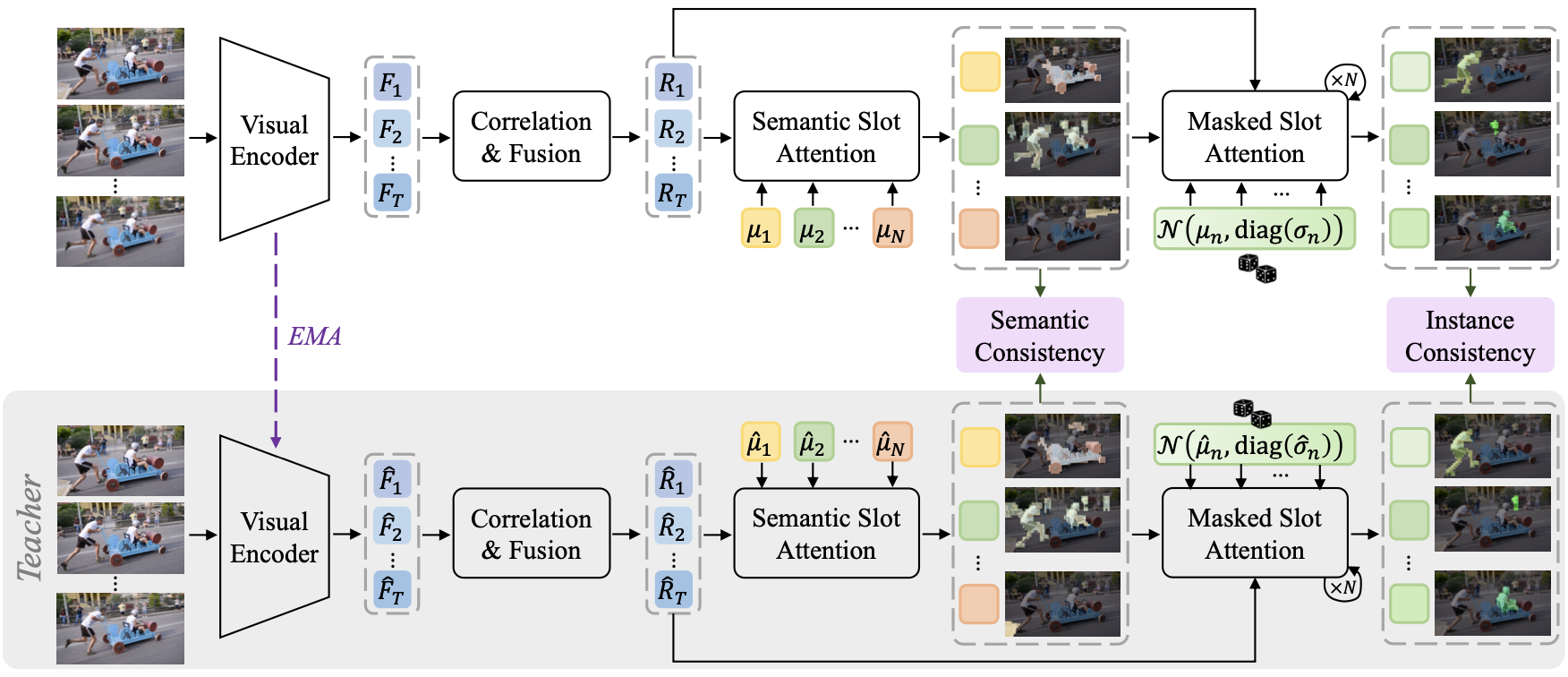
Zhixiong Zhang, Shuangrui Ding, Xiaoyi Dong, Songxin He, Jianfan Lin, Junsong Tang, Yuhang Zang, Yuhang Cao, Dahua Lin, Jiaqi Wang ICLR, 2026 Project Page / arXiv / code / HF model / HF benchmark Propose a VOS framework that leverages VLM for scene-level concept modeling, along with a new benchmark. |
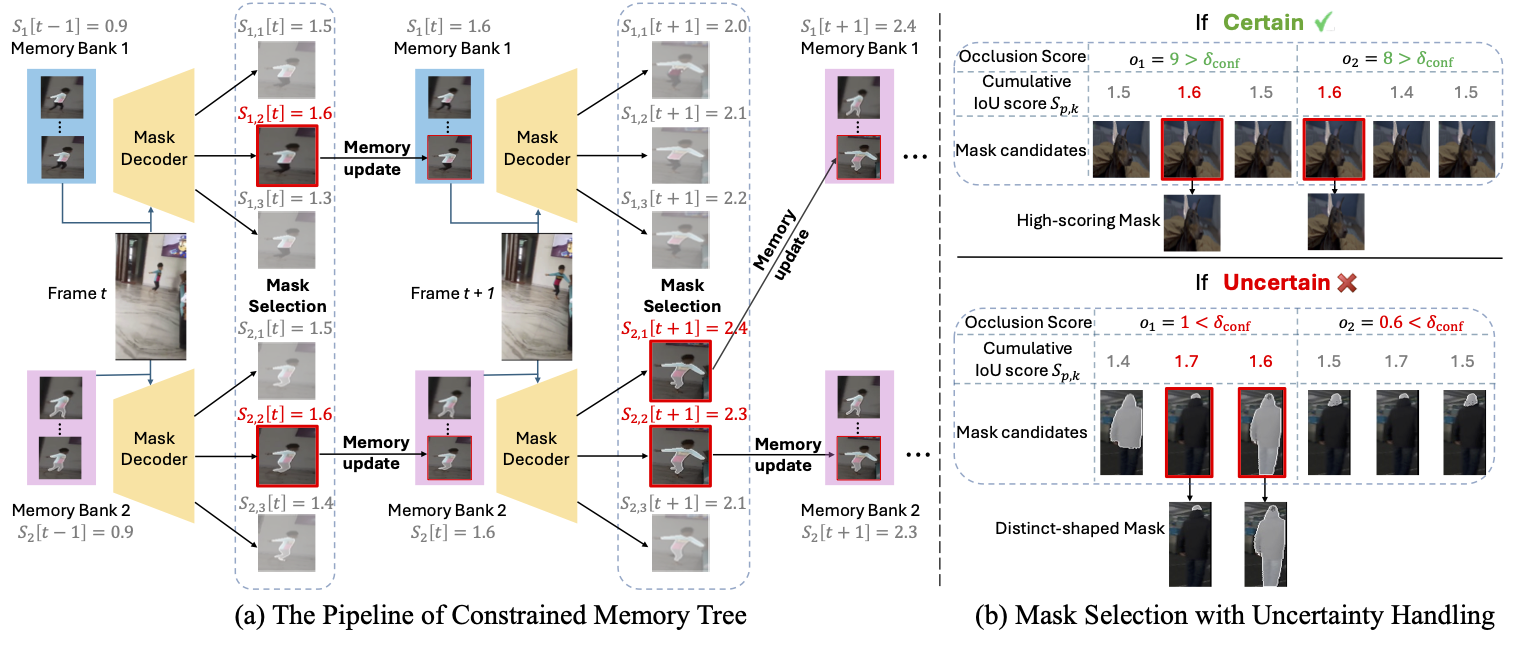
|
Shuangrui Ding, Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Yuwei Guo, Dahua Lin, Jiaqi Wang ICCV, 2025 Project Page / arXiv / code / PDF / poster Outperform SAM 2 by a large margin through a training-free memory tree. |

|
Shuangrui Ding*, Zihan Liu*, Xiaoyi Dong, Pan Zhang, Rui Qian, Junhao Huang, Conghui He, Dahua Lin, Jiaqi Wang ACL main, 2025 arXiv / code / invited talk / demo page A language large model that understands and generates melodies and lyrics in symbolic song representations. |

|
Rui Qian*, Shuangrui Ding*, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, Jiaqi Wang CVPR, 2025 arXiv / code Asynchronous operation of disentangled perception, decision, and reaction modules for online video LLMs. |
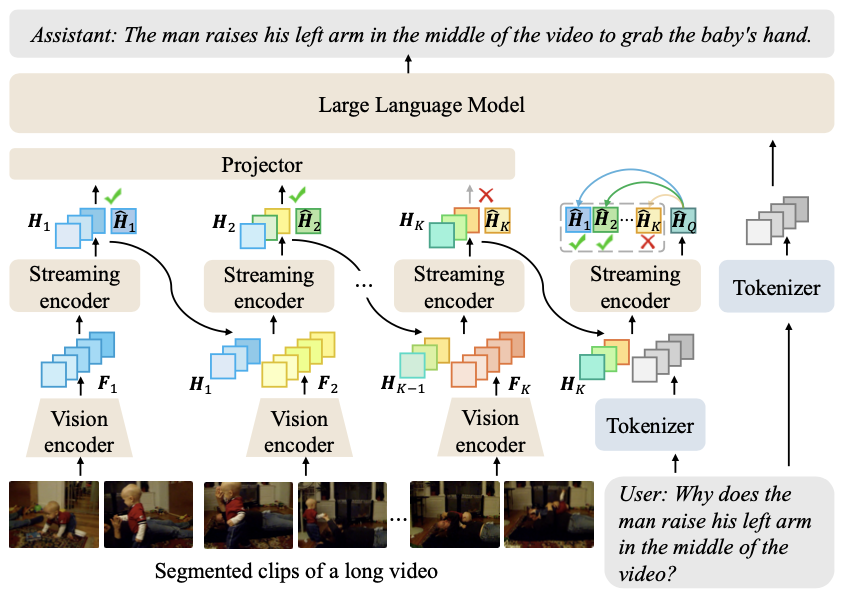
|
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, Jiaqi Wang NeurIPS, 2024 arXiv Long video understanding with disentangled streaming video encoding and LLM reasoning. |
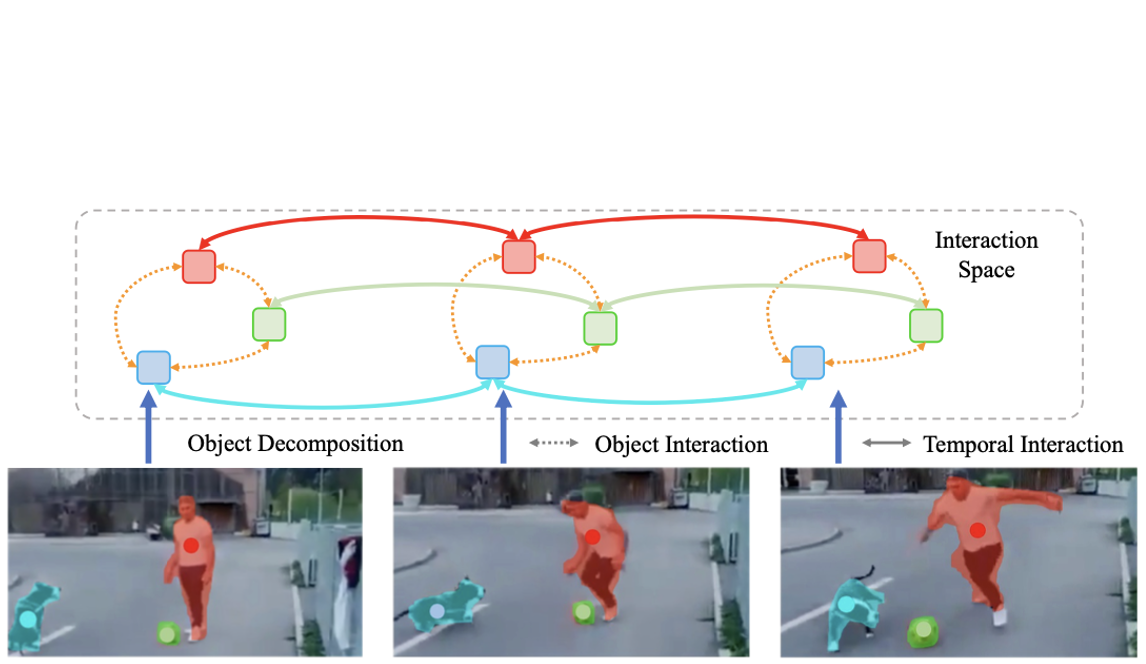
|
Rui Qian, Shuangrui Ding, Dahua Lin, ECCV, 2024 arXiv Efficiently adapt image foundation models to video domain in an object-centric manner. |
|
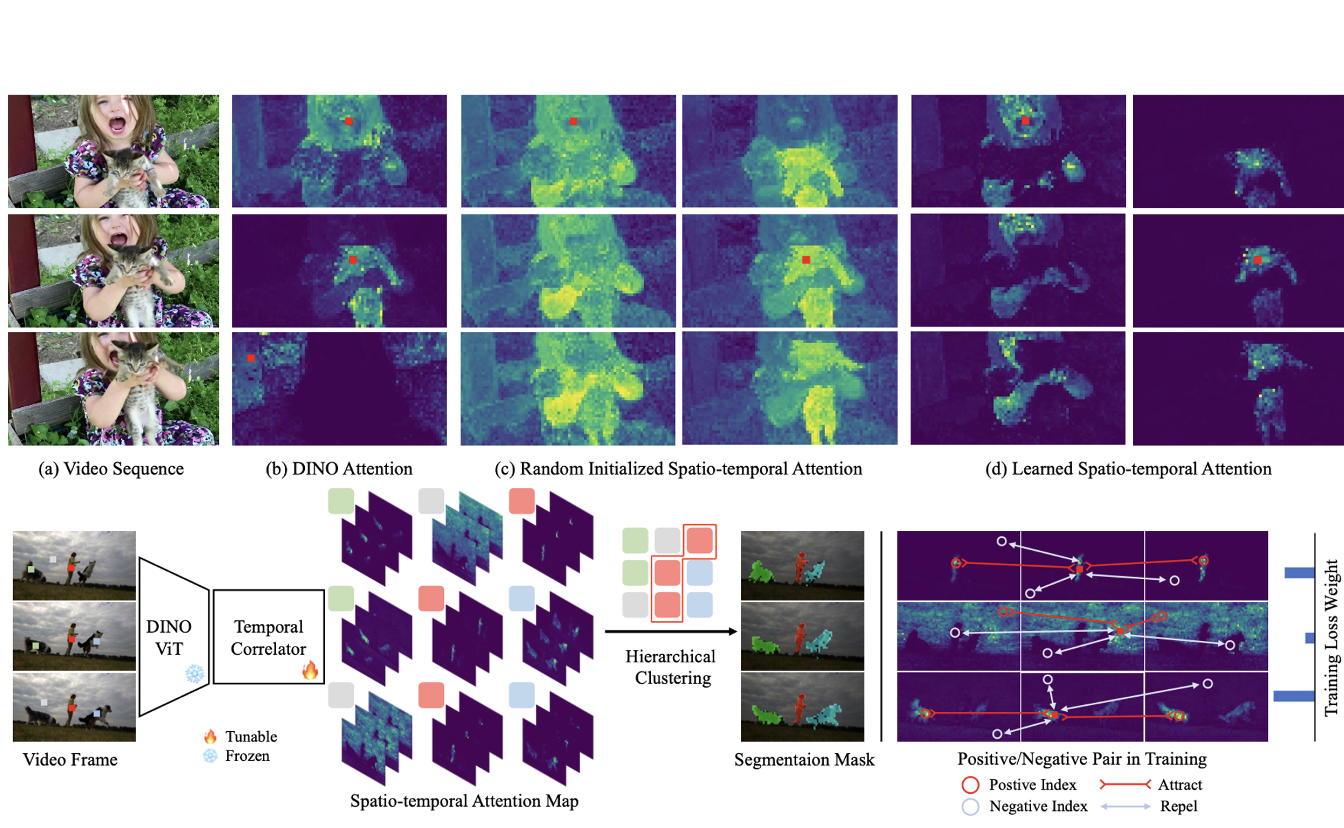
Shuangrui Ding*, Rui Qian*, Haohang Xu, Dahua Lin, Hongkai Xiong ECCV, 2024 arXiv / code Learn robust spatio-temporal corrependence on top of DINO-pretrained Transformer without any annotation. |
|
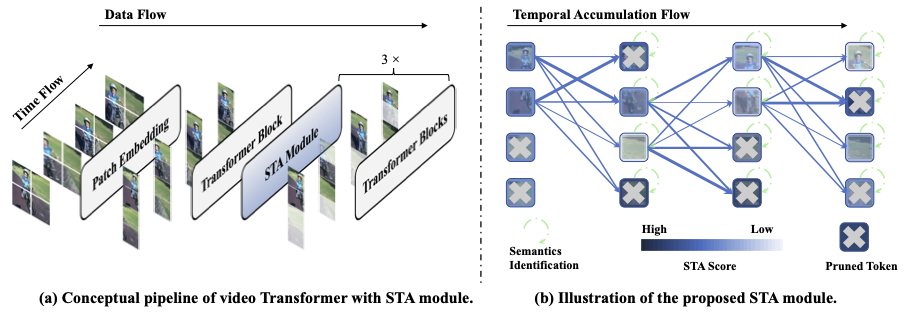
Shuangrui Ding, Peisen Zhao, Xiaopeng Zhang, Rui Qian, Hongkai Xiong, Qi Tian ICCV, 2023 Project page / arXiv / pdf / code / poster / slides Propose token pruning strategy for video Transformers to offer a competitive speed-accuracy trade-off without additional training or parameters. |
|
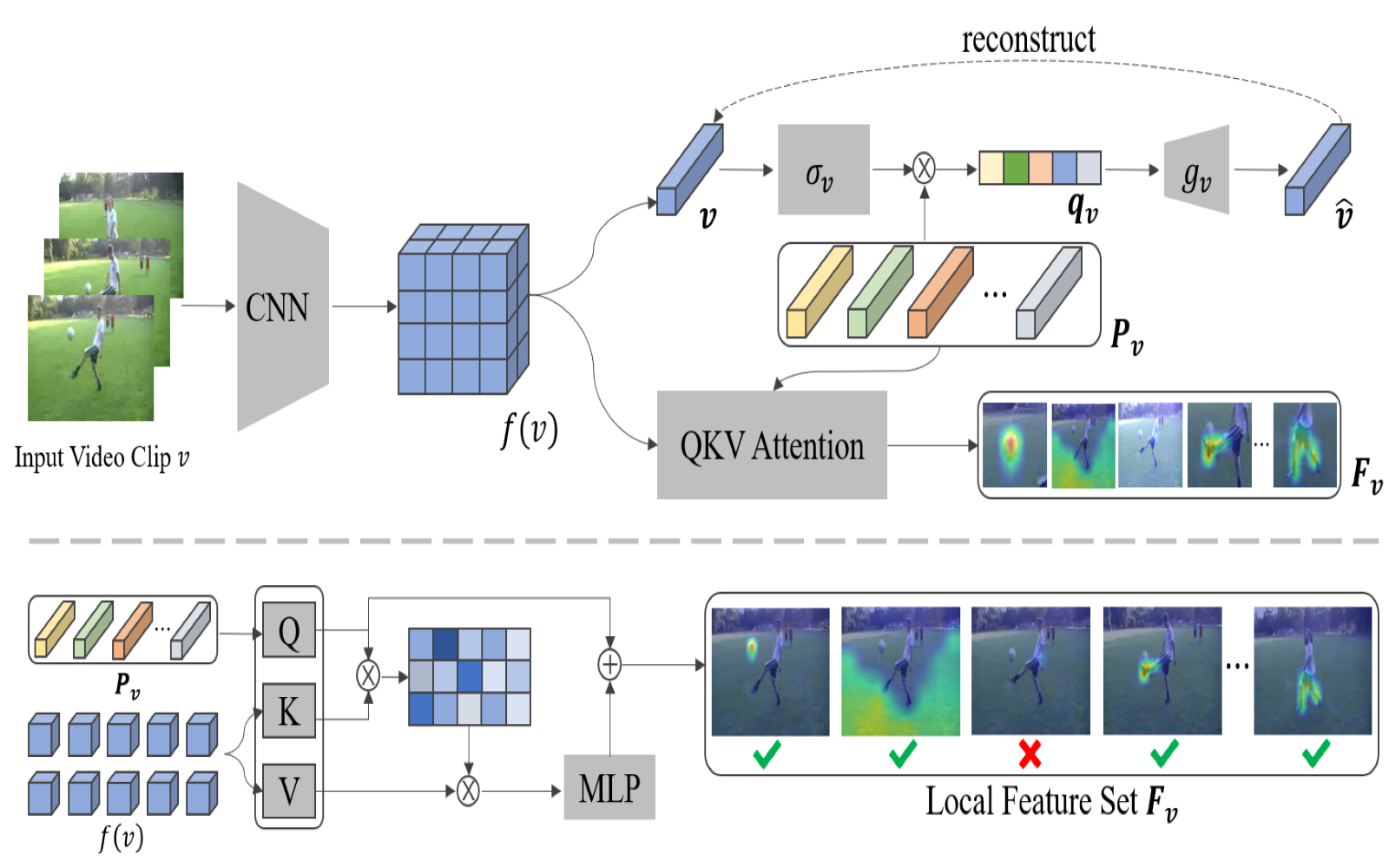
Rui Qian, Shuangrui Ding, Xian Liu, Dahua Lin ICCV, 2023 arXiv / pdf / code / poster Jointly utilizes high-level semantics and low-level temporal correspondence for object-centric learning in videos without any supervision. |
|
Rui Qian, Shuangrui Ding, Xian Liu, Dahua Lin ECCV, 2022 arXiv / code / slide Learn static and dynamic visual concepts in videos to aggregate local patterns with similar semantics to boost unsupervised video representation. |
|
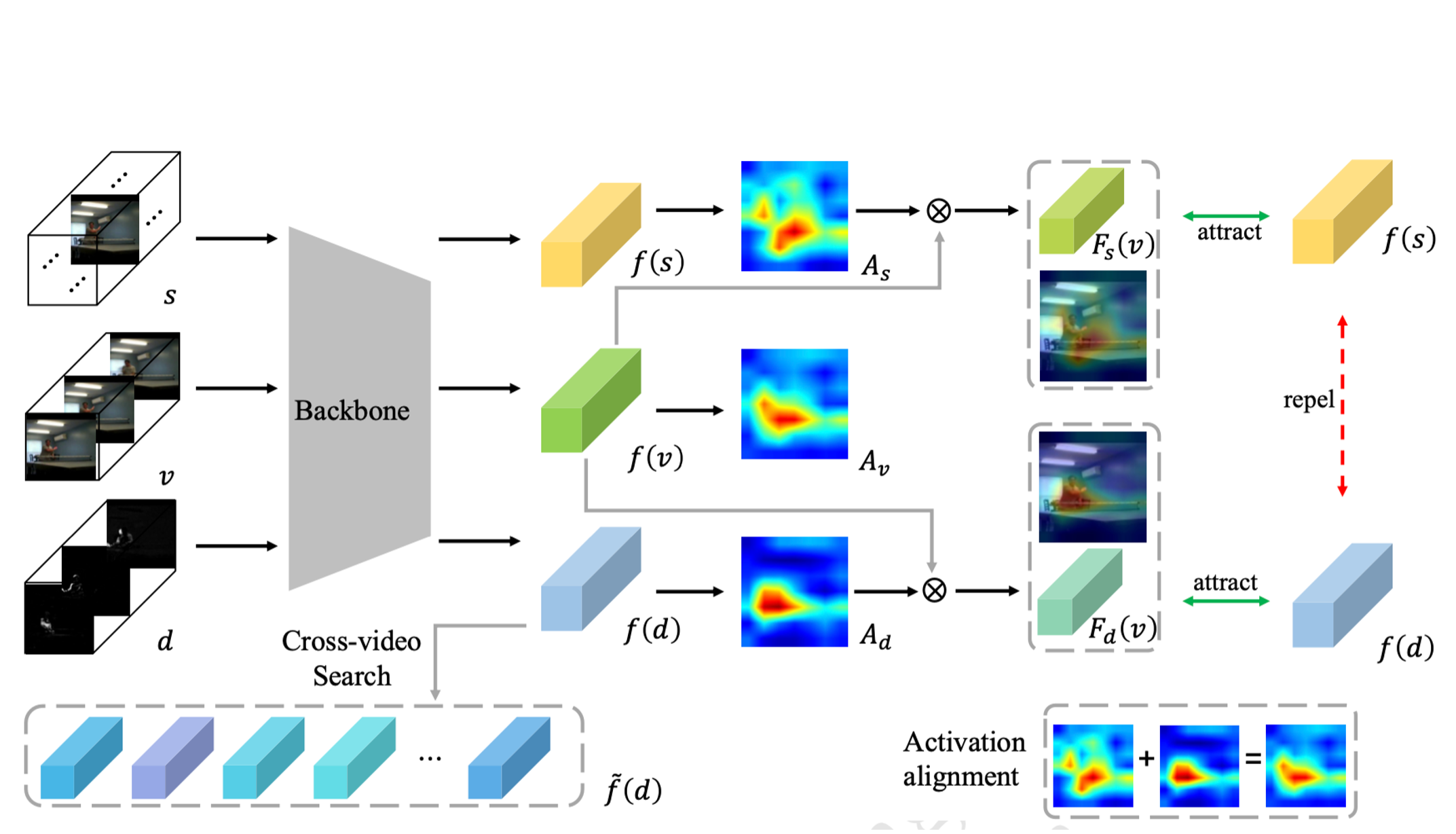
Shuangrui Ding, Rui Qian, Hongkai Xiong ACM MM, 2022 arXiv / poster / video / code Present a novel dual contrastive formulation to decouple the static/dynamic features and thus mitigate the background bias. |
|
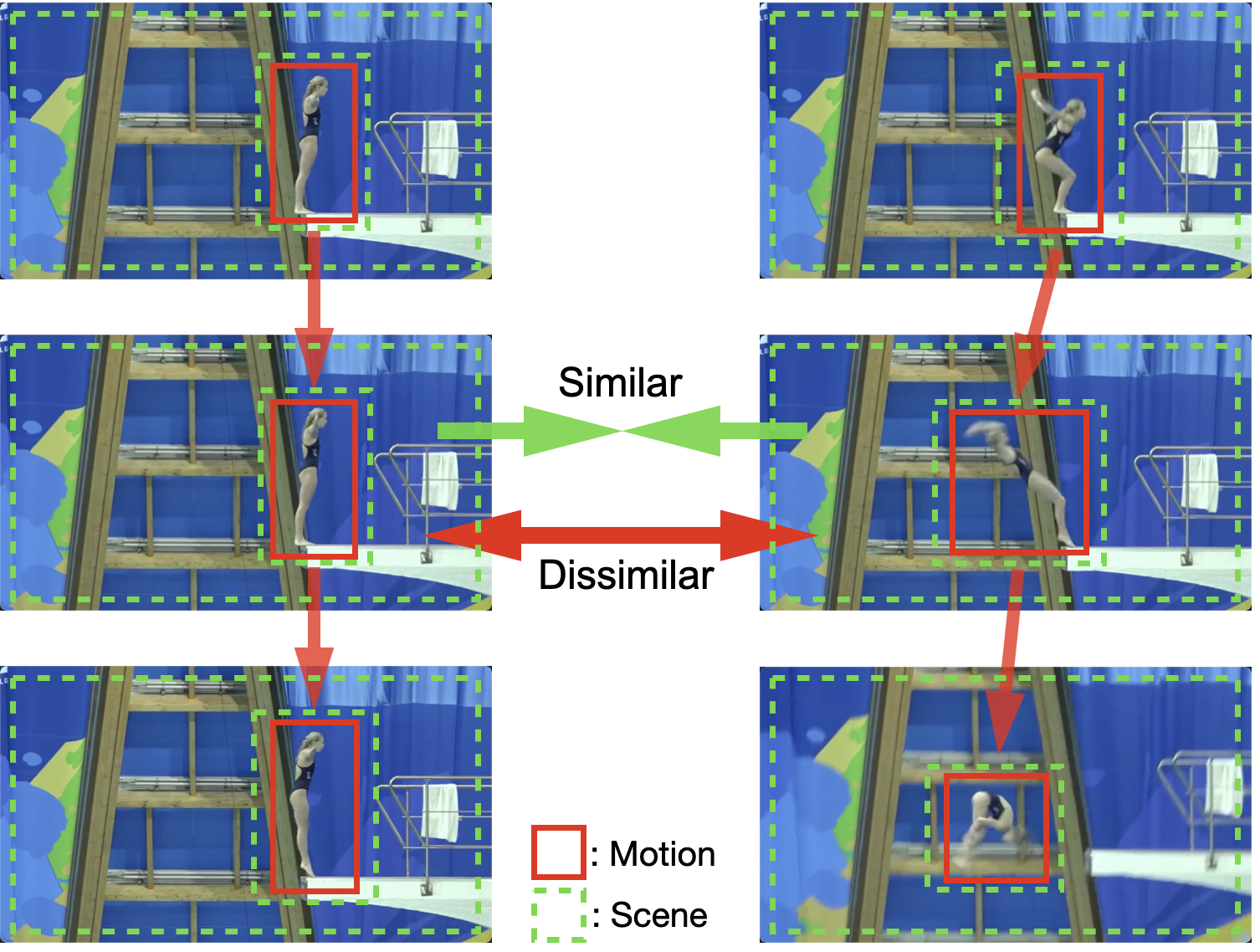
Shuangrui Ding, Maomao Li, Tianyu Yang, Rui Qian, Haohang Xu, Qingyi Chen, Jue Wang, Hongkai Xiong CVPR, 2022 Project page / arXiv / code / Chinese coverage / poster Mitigate the background bias in self-supervised video representation learning via copy-pasting the foreground onto the other backgrounds. |
|
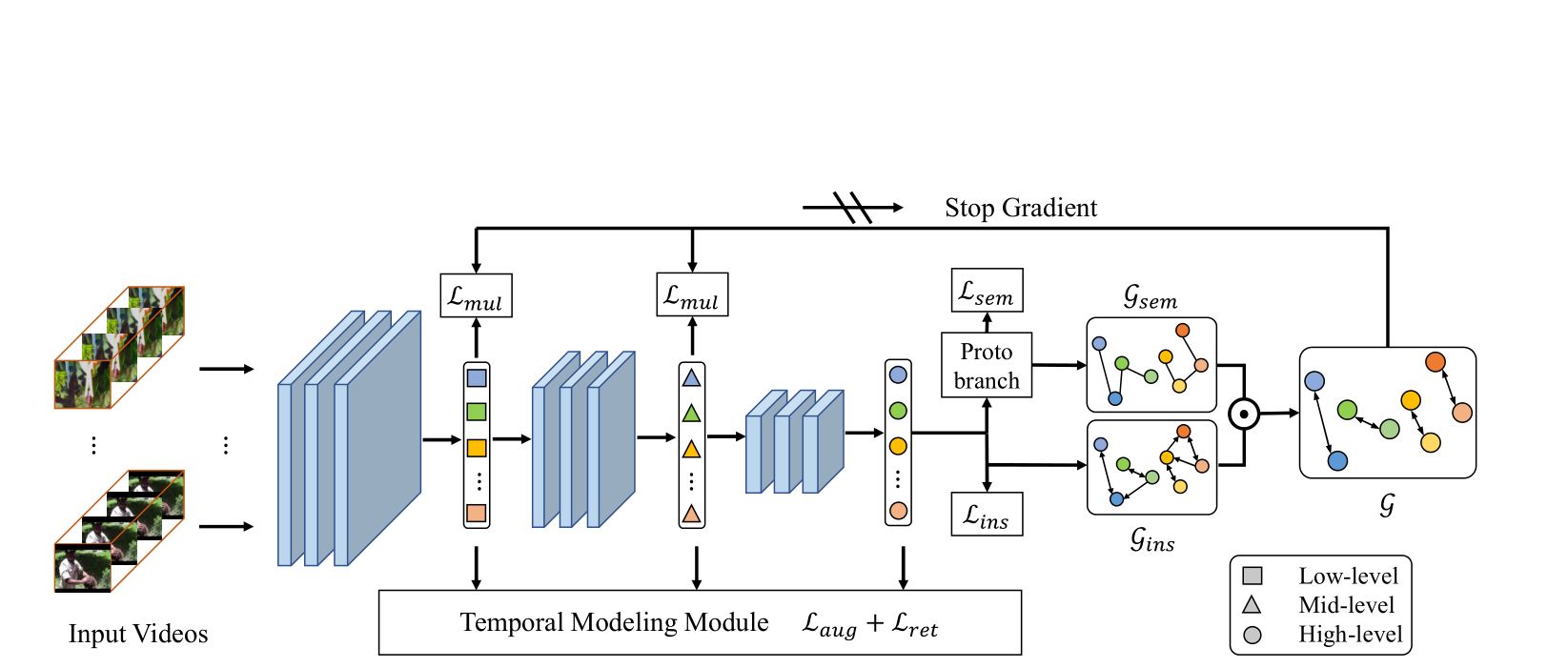
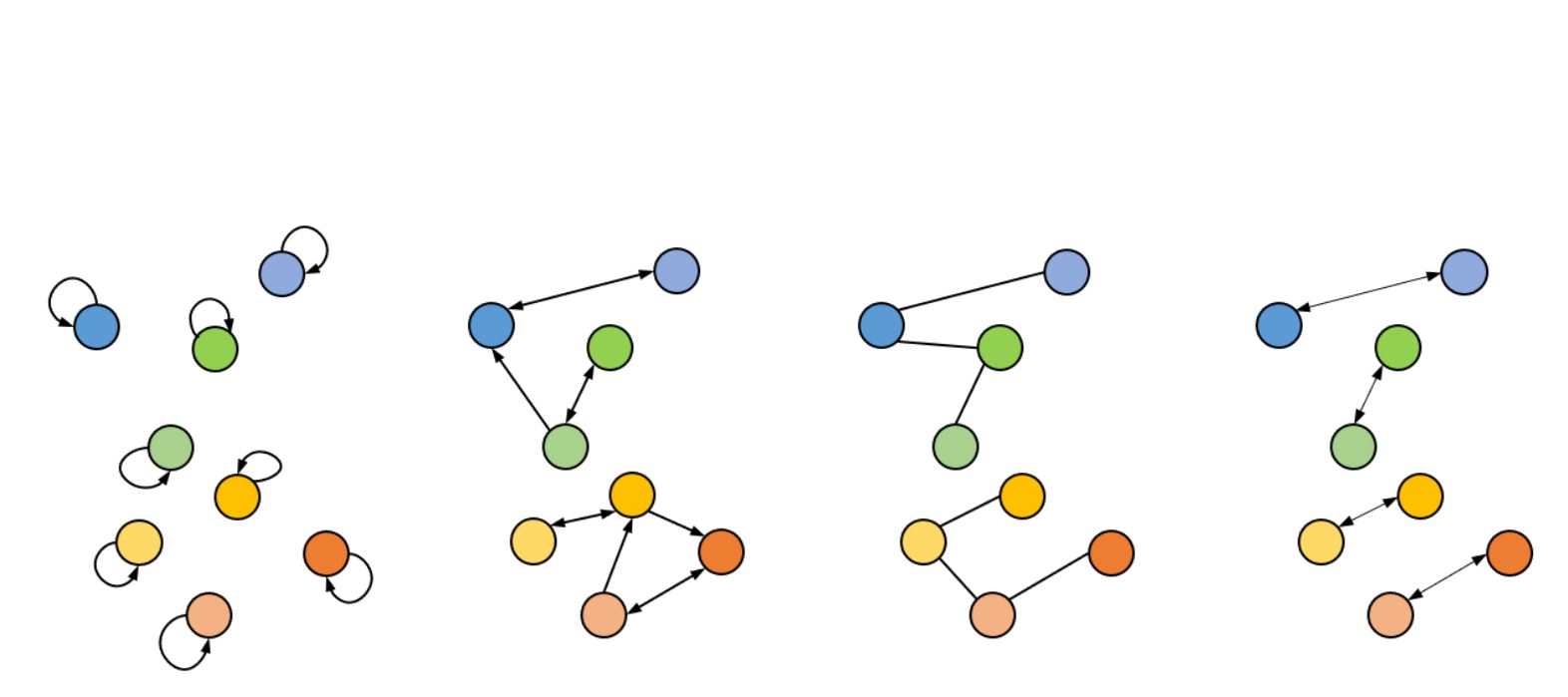
Rui Qian, Yuxi Li, Huabin Liu, John See, Shuangrui Ding, Xian Liu, Dian Li, Weiyao Lin ICCV, 2021 arXiv / code Self-supervised video representation learning from the perspective of both high-level semantics and lower-level characteristics |
|
Jiaqi Ma*, Shuangrui Ding*, Qiaozhu Mei NeurIPS, 2020 arXiv / slides / video / code Exploiting the structural inductive biases of GNNs, the restricted black-box adversarial attacks can be conducted effectively. |
|
CUHK Vice-Chancellor's Ph.D. Scholarship (80,000 HKD), Graduate school of CUHK. 2023 Graduate National Scholarship (Top 2%), Ministry of Education of China. 2022 Shanghai Excellent Graduate (Top 5%), Shanghai Municipal Education Commission. 2021 Finalist winner (Top 0.3%), Mathematical Contest in Modeling. 2019 National Scholarship (Top 2%), Ministry of Education of China. 2018 |
|
|
|
|
|
1. My favorite sports is soccer. I was the captain of UM-SJTU JI soccer team during season 2018. Besides, I am a super fan of Manchester City in Premier League. 2. I am proud that I have graudated from the competition class at Hangzhou No.2 High school, where I make friends with so many talented students and prestigious teachers. 3. It is worth mentioning that Rui is my best friend and has motivated me forward for over ten years as my role model. Best wishes and good luck! |
|
Updated at Feb. 2026
Thanks Jon Barron for this amazing template.
|