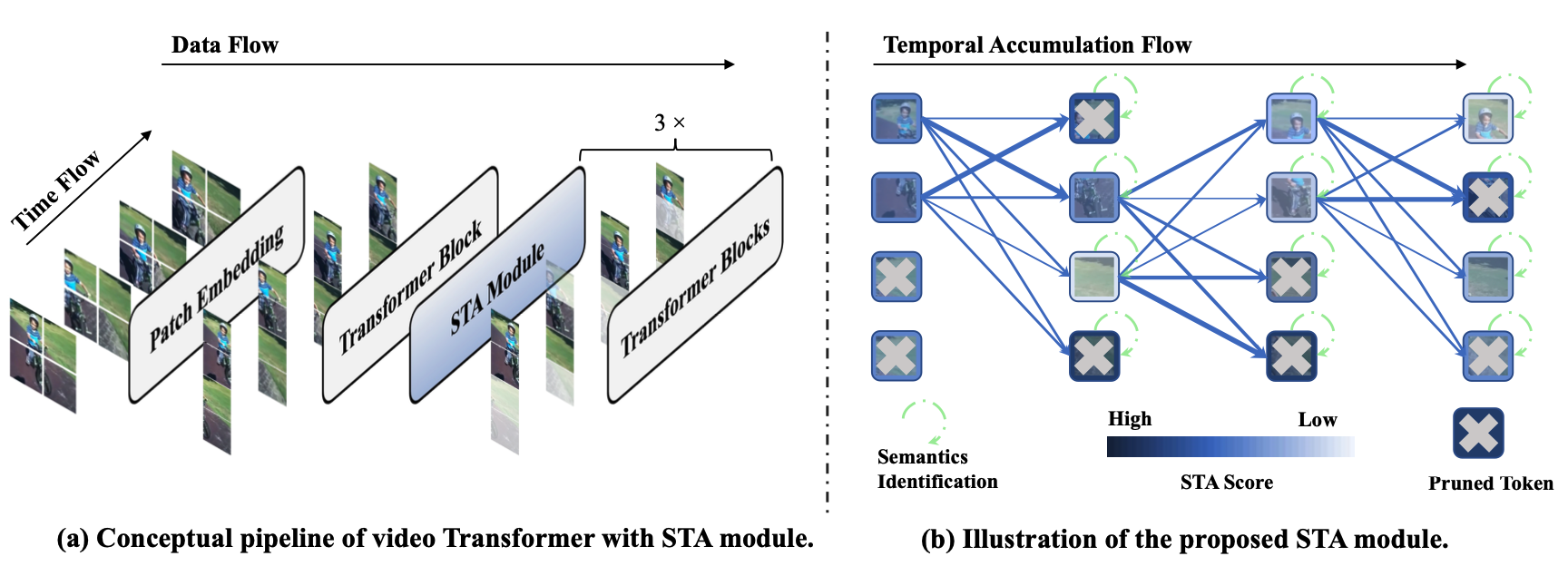
Abstract
Transformers have become the primary backbone of the computer vision community due to their impressive performance. However, the unfriendly computation cost impedes their potential in the video recognition domain. To optimize the speed-accuracy trade-off, we propose Semantic-aware Temporal Accumulation score (STA) to prune spatio-temporal tokens integrally. STA score considers two critical factors: temporal redundancy and semantic importance. The former depicts a specific region based on whether it is a new occurrence or a seen entity by aggregating token-to-token similarity in consecutive frames while the latter evaluates each token based on its contribution to the overall prediction. As a result, tokens with higher scores of STA carry more temporal redundancy as well as lower semantics thus being pruned. Based on the STA score, we are able to progressively prune the tokens without introducing any additional parameters or requiring further re-training. We directly apply the STA module to off-the-shelf ViT and VideoSwin backbones, and the empirical results on Kinetics-400 and Something-Something V2 achieve over 30% computation reduction with a negligible ∼0.2% accuracy drop. The code is released at here.
Publications
|
Prune Spatio-temporal Tokens by Semantic-aware Temporal Accumulation.
ICCV, 2023
|
Acknowledgements
Webpage template modified from Richard Zhang.